La compression de données - Méthodes LZ*
Les algorithmes à dictionnaire, aussi appelés substitution de facteurs, consistent à remplacer des séquences (les facteurs) par un code plus court qui est l?indice de ce facteur dans un dictionnaire. Contrairement à Huffman, cette compression recherche des récurrences de mots. On emploie ici une méthode de substitution de texte par un autre, plus précisément une chaîne de caractères par un entier long. Pour ce faire, on utilise un dictionnaire dans lequel on stocke le texte.
1-La compression LZ77 (base de pkzip, arj, gzip?)
Le premier algorithme de ce type a été publié par Lempel et Zif en 1977 sous le nom de LZ77, et a relancé la recherche dans la compression par son efficacité révolutionnaire.
L'algorithme utilise le principe d'une fenêtre coulissante de longueur N caractères, divisée en 2 parties, qui se déplace sur le texte de gauche à droite. La seconde partie, qui est la première à rencontrer le premier caractère du texte, contient F caractères : c'est le tampon de lecture. La première partie, alors égale à (N - F) sera appelée D . C'est le dictionnaire.
Initialement, la fenêtre est située D caractères avant le début du texte, de façon à ce que le tampon de lecture soit entièrement positionné sur le texte, et que le dictionnaire n'y soit pas. Les D caractères sont alors des espacements.
A tout moment, l'algorithme va rechercher, dans les D premiers caractères de la fenêtre, le plus long facteur qui se répète au début du tampon de lecture. Il doit être de taille maximale F. Cette répétition sera alors codée par le triplet (pos, size, char) :
- pos est la distance entre le début du tampon et la position de la répétition dans le dictionnaire.
- size est la longueur de la répétition.
- char est le premier caractère du tampon différent du caractère correspondant dans le dictionnaire.
La répétition peut chevaucher le dictionnaire et le tampon de lecture.
Après avoir codé cette répétition, la fenêtre coulisse de size + 1 caractères vers la droite. Le codage du caractère c ayant provoqué la différence est indispensable dans le cas où aucune répétition n'est trouvée dans le dictionnaire. On codera alors (0, 0, char ).
Compression
Soit le texte à coder " how-much-wood-would-a-woodchuck " en entrée.
On choisit une fenêtre de 21 caractères. Cette fenêtre sera donc coupée en deux parties :
La première représentant donc la partie lue qui sera de 16 caractères et la seconde étant alors de 5 caractères représentant le buffer de codage.
16 caractères de partie lue 5 caractères de buffer
Pour des raisons de rapidité, nous avancerons déjà la fenêtre sur le texte. Nous prendrons donc au départ :
ho | w-much-wood-woul | d-a-w | oodchuck
Nous remarquons que la chaîne ?d-? se retrouve déjà dans la fenêtre de pré-lecture.
Elle sera donc codée puis remplacée par son code dans le fichier de sortie. Ce code sera donc le suivant : (6, 2, a). 6 représente la position du début de l?équivalence en partant de la fin de la fenêtre de pré-lecture (partie italique). 2 est la longueur de la chaîne équivalente, et ?a? est le caractère suivant dans le buffer qui n?a pas pu être compressé.
On déplace ensuite la fenêtre de 3 caractères. Ce qui donne alors :
how-m | uch-wood-would-a | -wood | chuck
On remarque que toute la chaîne contenue dans buffer à une équivalence dans la fenêtre de pré lecture. On a alors le code suivant qui remplacera la chaîne dans le fichier de sortie : (13, 5, c). Nous voyons ainsi que la longueur maximale de l?équivalence sera donc la taille du buffer. Cela implique aussi que lorsque l?équivalence sera maximale, on devra chercher le caractère suivant qui ne se trouve pas dans ce buffer.
On déplace encore la fenêtre de la taille de l?équivalence + 1 et on tombe alors sur le cas suivant :
how-much-wo | od-would-a-woodc | huck
On tombe alors sur le cas où il n?y a pas d?équivalence entre le buffer et la fenêtre de pré-lecture. On remarque alors une des plus grosses faiblesses de cet algorithme : comme il n?y a pas d?équivalence, on code le premier caractère du buffer par le triplet (0,0,h). On décale ensuite la fenêtre d?un caractère. La faiblesse est donc que lorsqu'on ne trouve pas d?équivalence, un caractère prend plus de place qu?un octet!
On continue ensuite l?algorithme jusqu?à ce que l?on n?ait plus aucun caractère dans le buffer.

Voir le document LZ77.ppt.
Décompression :
La décompression est très simple et rapide. A partir de la suite de triplets, le décodage s'effectue en faisant coulisser la fenêtre comme pour le codage. Le dictionnaire est donc reconstruit de gauche à droite en une seule fois.
On reprend l?exemple que l?on avait précédemment, c'est-à-dire l?expression " how-much-wood-would-a-woodchuck ". On garde alors notre fenêtre de pré-lecture de 16 caractères, on a donc :
ho | w-much-wood-woul
Et on a dans le fichier à décompresser le mot codé suivant : (6, 2, a)
ho | w-much-wood-woul
On repère donc dans la chaîne l?équivalence indiquée c'est-à-dire la chaîne de 2 caractères qui se trouve en 6e position en partant de la fin de la fenêtre. Soit ici : ?d-?.On ajoute donc cette chaîne avec le caractère ?a? indiqué à la suite de la fenêtre.
ho | w-much-wood-woul | d-a
On décale la fenêtre de la taille de la chaîne ajoutée soit : 3 caractères.
how-m | uch-wood-would-e
On arrive au code (13, 5, c). Ce qui nous donne ainsi :
how-m | uch-wood-would-a | -wood
On déplace de nouveau la fenêtre de la taille de l?équivalence + 1 :
how-much-wo | od-would-a-woodc
On continue ainsi de suite jusqu?à ce qu?il ne reste plus de données dans le fichier en entrée.
Avantages :
L'algorithme comprime les informations au fur et à mesure du déplacement de la fenêtre. Contrairement à Huffman, il n'a besoin que d'un seul passage sur la chaîne à coder. Il peut donc être utilisé sur des données en transit. C'est pourquoi la norme V42bis des modems utilise la compression LZ77 pour réduire la quantité de données à télécharger. Il faut bien sûr que la mémoire du modem soit suffisante pour contenir la fenêtre de l'algorithme.
On peut ainsi dépasser la valeur maximale indiquée par le constructeur (33,6 Kbps, 56 Kbps?).
Une décompression très rapide.
Consommation en mémoire très faible dépendant de la taille de la fenêtre.
Inconvénients :
Malgré les énormes avantages de cette méthode de compression il réside des inconvénients non négligeables qui vont faire évoluer cet algorithme.
Nous remarquons que lorsqu?un caractère n?a pas été compressé nous obtenons 2 informations inutiles à partir d?un triplet (0, 0, char), nous utilisons plus que 8 bits pour coder un caractère, ainsi pour un fichier peu compressible le gain risque d?être faible voir négatif. Le LZSS va corriger ce problème et offrir un taux de compression bien plus important.
La mise en place du compresseur et décompresseur LZ77 est fastidieuse, en effet le manque d?informations sur les algorithmes nous on contraint à un développement assez long.
La compression est très lente malgré l?utilisation d?un processeur puissant, le problème est de trouver la plus grande équivalence au plus vite. La méthode brutale qui consiste à tester une par une les équivalences, n?est pas acceptable. Les logiciels de compression utilisent des techniques pour pallier à ce problème tel que les ABR (Arbres Binaires de Recherche) ou encore les tables de hachages et même une programmation en assembleur. Nos algorithmes LZ77, LZSS ne possèdent aucun technique cité contrairement à LZW qui manipule les ABR et tables de hachages. A partir du logiciel nous pourrons comparer les vitesses de compression entre LZ77, LZSS et LZW.
La compression LZ77 est utilisée dans les modems et les logiciels de compression tel que Winzip qui combine LZ77 avec Huffman (compression nommée LZH).
2-La compression LZSS.
Le LZSS est une énorme amélioration du LZ77, il faut souligner que LZSS est aujourd?hui couramment appelé LZ77 puisque l?ancienne version n?est plus utilisée.
Nous avons vu tout à l?heure que LZ77 possède un énorme défaut lorsqu?un caractère n?a pas pu être compressé. Pour remédier à ce problème, LZ77 utilise une méthode ingénieuse avec l?utilisation d?un marqueur qui indique si la donnée suivante est un caractère seul (donc non compressé) ou une paire (position, longueur). Ce marqueur doit être codé sur un seul bit pour ne pas pendre plus de place que nécessaire.
Diaporama : La compression LZSS
La compression :
La compression LZSS se fait de la même manière que LZ77 excepté le fait qu?on puisse tomber face à deux cas de figure pour le mot codé :
·On a un triplet (marqueur, position, longueur) quand on compresse la donnée.
·On a juste un couple (marqueur, caractère non compressé) quand on ne compresse pas.
Le marqueur est à 1 lorsque la donnée qui suit est la paire (position, longueur), et 0 si on a simplement le caractère non compressé à la suite.
On recherche toujours une équivalence entre le buffer et la fenêtre de pré lecture. Ici encore, il vaut mieux que cette recherche soit faite grâce à l?utilisation d?un arbre de recherche, par hachage ou par d?autres méthodes avancées.
Reprenons l?exemple du départ pour examiner les différences :
ho | w-much-wood-woul | d-a-w | oodchuck
On procède de la même manière : on voit qu?il y a équivalence entre le buffer et la fenêtre de pré lecture. Le code de la donnée compressée est alors : (1, 6, 2), et on décale alors la fenêtre de 2 caractères.
how- | much-wood-would- | a-woo |dchuck
Maintenant, nous ne trouvons pas d?équivalence dans la fenêtre, on a alors le code suivant qui est rajouté au fichier de sortie : (0, a). Il ne faut pas oublier que le marqueur n?est dans tous les cas codés que sur 1 bit et non 1 octet !
On décale la fenêtre d?un caractère.
how-m | uch-wood-would-a | -wood | chuck
On retombe alors sur une équivalence et le code en résultant est : (1, 13, 5), on déplace alors la fenêtre de 5 caractères?. Et ainsi de suite jusqu?à ce qu?il n?y ait plus de caractères en entrée dans le buffer.
La fenêtre de pré lecture
Si l?on regarde à nouveau les exemples, nous nous devons de détailler la fenêtre de lecture. En effet, dans la pratique, il y a quelques contraintes à suivre.
Tout d?abord, il faut savoir que le principe est simple mais sa représentation informatique ne l?est pas forcément ! Il faut ainsi regarder en arrière pour les équivalences, c'est-à-dire dans les données qui ont déjà été traitées. La fenêtre n?est donc qu?un buffer qui contient les caractères qui sont avant la position courante dans le fichier. Chaque caractère qui sort non compressé est ajouté à ce buffer mais aussi les caractères qui sont codés.
Or, comme on peut le voir, lorsqu'on recherche des équivalences, nous comparons des données qui sont dans la fenêtre de pré lecture avec les données qui sont à la position courante. Nous avons ainsi deux possibilités :
1 ? On garde un buffer à la position courante dans le fichier et un autre avec la fenêtre de pré lecture. Cette implémentation est possible mais assez lourde à gérer.
2 ? On a simplement un buffer qui contiendra toutes les données puisque a fenêtre de pré lecture et les données à la position courante ne sont rien d?autre que le fichier. Nous n?avons ainsi qu?à nous soucier du pointeur qui marquera la position actuelle dans le fichier, la fenêtre de pré lecture se trouvant alors juste avant.
C?est cette solution qui est la plus couramment utilisée.
Il faut aussi prendre en compte la taille de la fenêtre. Il serait possible de prendre tout le début du fichier jusqu?à la position courante, mais il faut penser au travail de recherche de la plus grosse équivalence qui sera de plus en plus long. Il faut aussi prendre en compte tout simplement la taille du codage de la position de l?équivalence. Plus grande est la fenêtre et plus grand risque d?être le nombre de bits utilisés pour coder cette position. Donc, nous devons obligatoirement choisir une taille pour la fenêtre de pré lecture. En général, on utilise 4096 octets (caractères), mais faut aussi savoir que plus la fenêtre est grande, et meilleure sera la compression. Ainsi, si l?on prend une taille de 4096 octets, nous aurons besoin de 12 bits pour coder la position.
Le codage de la longueur
Un autre paramètre est à prendre en compte, la longueur du codage de la longueur. Combien doit-on utiliser de bits pour coder la longueur de l?équivalence? En général, une longueur maximale de 32 caractères est suffisante, ce qui représente seulement 5 bits.
Il faut aussi tenir compte d?une longueur minimum pour l?équivalence. On a choisit d?utiliser ici 12 bits pour la position et 5 pour la longueur, soit 17 bits en tout. Ainsi, une équivalence devra être d?au moins 3 caractères pour être avantageuse. Parce que si on code une équivalence de 2 caractères, soit 2 octets et qu?on en utilise alors 17 bits pour la position et la longueur, on utilise alors 1 bit de trop. Cela peut paraître peu, mais dans certains cas, cela peut être très néfaste.
On peut de plus tirer profit de cet avantage : on n?a pas d?équivalence de 0, 1 ou 2 caractères, donc, en gardant le codage de la longueur sur 5 bits, on peut coder une longueur de 3 à 35 caractères équivalents ! Il suffit de soustraire 3 à la longueur à chaque fois qu?on compresse et d?ajouter 3 quand on décompresse.
3-La compression LZ78 (LZW).
Cette méthode de compression est assez différente de LZ77 et surtout adapté seulement aux images. La compression GIF utilise cet algorithme.
L'algorithme LZW est un algorithme de compression de type dictionnaire résolvant trés efficacement les problèmes cléf tels que le stockage et la gestion du dictionnaire. Il porte le nom de ses trois inventeurs : Lempel et Ziv qui l'ont conçu en 1977, et Welch qui l'a finalisé en 1984.
Analyse :
Pour proposer une analyse rapide de cette méthode de compression, on peut séparer quatre grandes étapes :
1) Analyse du flux d?entrée
2) Comparaison entre les valeurs lues en entrées et celles contenues dans le dictionnaire
3) Ajout de nouvelles phrases dans le dictionnaire
4) Codage du texte clair et des index du dictionnaire de manière différente pour éviter de les confondre lors de la décompression
De même pour la décompression, on distingue quatre étapes :
1) Décoder les entrées qui sont des index du dictionnaire de celles qui sont du texte en clair
2) Ajouter des nouvelles phrases au dictionnaire
3) Convertir les index du dictionnaire par leur équivalence
4) Emettre le texte en clair
Nous allons traiter une chaîne par l'algorithme LZW, pour nous familiariser avec celui-ci. Ceci nous facilitera grandement la lecture de l'algorithme présenté dans la section suivante. La chaîne considérée est :
"AIDE TOI LE CIEL T AIDERA"
L'objectif de l'algorithme LZW est de construire un dictionnaire où une séquence qui sera désignée par une adresse dans le dictionnaire. On ne s'intéresse pas pour l'instant à la façon dont il est construit mais seulement à sa forme.
Sont considérées comme faisant implicitement partie du dictionnaire les motifs unitaires : les octets dont l'adresse correspond aux codes ascii de 0 à 255. Au delà de 255 commencent les motifs complexes qui sont les séquences originales rencontrées dans le texte. On y retrouve notamment "AI" présent deux fois dans le texte.
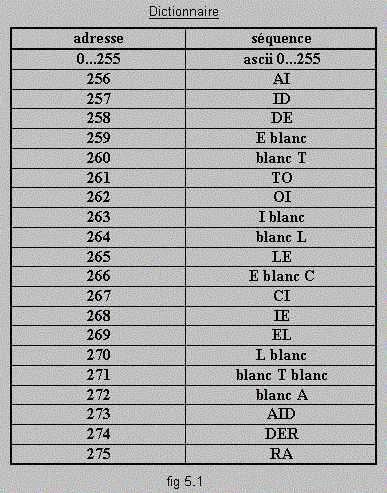
Intéressons nous maintenant à la construction du dictionnaire et à la création du fichier compacté. On y précise chronologiquement dans quatre colonnes différentes :
·les octets lus séquentiellement dans le fichier original : il sont lus les uns après les autres.
·Les adresses émises dans le fichiers compacté : leur concaténation forme le fichier compacté. Les adresses correspondent aux séquences écrites dans le dictionnaire. On trouve les adresses sous forme décimale et binaire pour constater les variations de taille des motifs.
·La chaîne tampon qui permet de mémoriser les chaînes rencontrées dans le texte et d'apprendre de nouveaux motifs.
·Le dictionnaire : on y trouve les ajouts séquentiels qui surviennent à chaque nouveau motif rencontré.
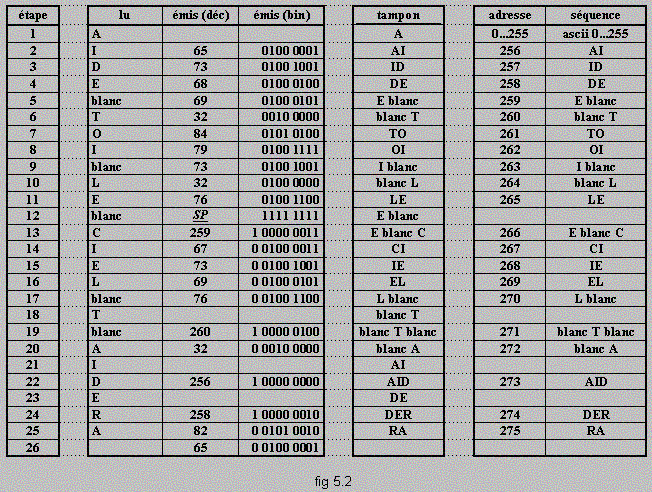
Les premières étapes du compactage sont les suivantes : le premier octet lu est "A". L?algorithme n'effectue que cette action à la première étape."A" est mémorisé dans un tampon T. Puis l'octet "I" est lu. On le place dans le tampon T qui contient alors "AI". On regarde si la chaine de T existe dans le dictionnaire. Elle n'existe pas, donc on ajoute la chaîne de T ("AI") dans le dictionnaire et on émet le code de "A" a défaut d'une chaîne plus longue. Ensuite on retire "A" de T et on recommence le processus.
Si la chaîne dans T existe dans le dictionnaire, on n'émet rien dans le fichier de sortie mais on lit le caractère suivant pour rechercher une chaîne plus longue. C'est ce qui se passe à l'étape 12 : "E blanc" est déjà dans le dictionnaire, on tente de chercher "E blanc C" à l'étape suivante. La recherche de "E blanc C" échoue et on émet le code de "E blanc" puis on garde seulement "C" dans T (le dernier caractère lu) : On se retrouve comme en phase d'initialisation.
On peut remarquer qu'à l'étape 12, au lieu de ne rien faire on a émis un code "SP" = 11111111. Ce code signifie qu'à partir de ce point les adresses ne seront plus émises sur 8 bits mais sur 9 bits, ceci pour permettre de gérer des adresses de tailles variables.
On tombe ici sur une caractéristique importante de l'algorithme LZW : le code "SP" est inutile au compacteur mais est par indispensable au décompacteur pour décoder les adresses. C'est que l'algorithme de compactage et de décompactage communiquent, l'un donnant à l'autre les informations dont il a besoin. Ce système est l'origine de très nombreuses variantes.
Lors de la décompression le dictionnaire est reformé au fur et à mesure selon le même principe que la compression. Lorsque l'algorithme rencontre une adresse supérieure à 255, celle-ci est obligatoirement déjà présente dans le dictionnaire ce qui assure du bon fonctionnement de l'algorithme.
Remarques sur la compression :
·L'existence du code "SP" est problématique : on ne peut à priori émettre le code ascii 255. Il s'agit encore ici que compacteur et décompacteur se mette d'accord sur un protocole. L'émission du code ascii 255 peut se faire en deux temps : d'abord "SP"=11111111 (8 bits), puis 011111111 (ascii 255 sur 9 bits). Cette solution n'est pas unique.
·Le code "SP" peut ne pas être le seul code de communication avec l'algorithme de décompression. D'autres codes peuvent par exemple servir à vider des dictionnaires périodiquement, à créer d'autres dictionnaires : il n'y a pas de limites.
·On peut remarquer que l'algorithme n'a pas repéré la redondance de "AIDE" présentes deux fois dans le fichier. C'est que l'algorithme présenté est une version qui lit le fichier à compresser octet par octet. On peut faire lire plusieurs octets du fichier pour y déceler des redondances d'ordre supérieur et ainsi détecter des chaînes plus longues.
Avantages :
L'algorithme LZ78 permet d'obtenir d'excellents taux de compression. Cependant il lui faut un minimum de caractère pour obtenir ces taux. Normalement, les statistiques montrent qu'à partir d'un fichier en entrée contenant au moins 1000 mots, on commence à obtenir des taux de compression de 50 %.
En plus d'un bon taux de compression, l'intérêt de LZ78 réside dans son mode de compression. Il nécessite qu'une seule lecture du fichier d'entrée. Construisant ainsi son dictionnaire au fur et à mesure, il permet d'éviter de le transmettre pour la décompression (il est reconstruit lors de la décompression). Ceci évite de nombreuses erreurs et assure un cycle de compression/décompression sans perte.
Ces quelques avantages de taille font de LZ78 un algorithme utilisé dans de nombreux logiciels commerciaux : Compress sous Unix, les pages "man" sous Linux. De plus, l'utilisation de cet algorithme se retrouve dans le monde de l'électronique sous forme de la puce QIC-122. Cette puce est particulièrement utilisée sur les disques durs. Celle ci permettrait de compresser des données en temps réels.
Enfin pour conclure sur les avantages de LZ78, on peut souligner que la norme V42.bis intègre cet algorithme. Cette norme définit le mode de compression standard utilisé dans les modems. Et il ne faut pas oublier le célèbre format d?image GIF qui utilise cette algorithme.
Au vu de son utilisation et de ses performances de compression, la méthode LZ78 reste, malgré son âge, une des meilleures et des plus sûres manières de compresser des données.
Inconvénients :
La principale difficulté de cet algorithme réside dans la gestion du dictionnaire. Nous pouvons alors dès à présent introduire la méthode LZW. En effet, en 1984 Terry Welsh apporte quelques améliorations à l'algorithme LZ78. La principale amélioration est d'initialiser le dictionnaire par un vocabulaire minimum. Terry Welsh a l'idée astucieuse d'initialiser ce dictionnaire par les 256 entrées du code ASCII.
Cette idée de Welsh permet donc de compresser le fichier dès le 1er caractère. Il n'améliore pas pour autant la gestion du dictionnaire mais seulement son efficacité. D'autres chercheurs ont apporté certaines avancées dans cette gestion ; leur idée principale étant de minimiser la recherche d'une chaîne dans le dictionnaire. La 1ère méthode évidente fut de classer les entrées du dictionnaire par ordre alphabétique. Cette première approche n'étant pas suffisante, l'idée fut proposée de faire un classement en fonction de la taille de la chaîne de caractère en cours de traitement. Il suffit alors de calculer la longueur de cette chaîne et de l'insérer dans le dictionnaire au bon endroit. Cette simple technique permet d'augmenter de 12 fois environ la vitesse de compression/décompression.
Les problèmes de dictionnaire étant partiellement résolus, il reste un dernier problème concernant l'algorithme LZ78. Il s'agit en fait du brevet déposé sur l'algorithme LZW. En effet en 1984, lorsque Terry Welsh publie son algorithme LZW, ce dernier obtient un brevet US protégeant en partie sa méthode de compression. Depuis ce brevet est devenu la propriété de Unysis, et bien que LZW dépende de LZ78, ce dernier n'est plus libre d'accès et d'utilisation. Réponse faite par Unysis au sujet de l'utilisation de LZW dans des logiciels :
"Dans tous les cas, une licence écrite ou un rapport signé par un représentant autorisé d'Unysis est exigé d'Unysis pour toute utilisation, vente ou distribution de n'importe quel logiciel (y compris les logiciels appelés "freeware"), et/ou matériel fournissant les capacités de conversion LZW (par exemple logiciel téléchargé)."
Il est donc clair que la version libre reste l'algorithme LZ78 qui lors de sa création n'avait pu obtenir un brevet (les brevets US ne furent distribués qu'à partir des années 1980).
Pour notre part nous avons développé le LZW en tant que la modification à apportée au LZ78 est très faible.
Pour optimiser la vitesse de compression il est préférable de coder les algorithmes en assembleur, d?autre pour être capable de gérer des messages de longueurs quelconques, des buffers circulaires, le programmeur doit mettre en place un système d'allocation dynamique de mémoire, toujours en assembleur.
4-La compression LZH.
Le LZH est une avancée moderne comparée au LZSS, permettant de combiner le LZSS avec Huffman adaptatif pour offrir un taux de compression presque optimal. Le c?ur de Winzip est basé sur le LZH, nous n?avons pas trouvé d?informations sur cette compression sur internet, nous empêchant ainsi de la développer.